Mistakes to avoid in large Firebase Firestore projects 💸
Firebase's Firestore is a NoSQL document database with great pricing and scalability. This scalability has some nuances and things you need to consider (and avoid) if you want to avoid cost, inefficiencies and sleepless nights.
Background
Recently at Stillio in a project that I manage - we had a special feature request from a customer. Our main service is to provide a web archiving solution through high fidelity, scheduled screenshots of provided page urls. Normally a user would enter either 1 url, or provide a sitemap of up to 500 urls, then they can manage their screenshotted pages' settings, like:
- timeslots
- scheduling
- sizing etc.
Going bigger
The special request was from a prominent site in the US to generate screenshots for batches of 15,000 per week. 😅
Needless to say, the heat was on. Our backend engineer did an amazing job at developing a solution that involves queues, lambdas and a whole lot more. We had a little more than a week to develop the solution and very early in the architectural decisions we hit a roadblock in the form of database. The physical screenshots weren't the problem, but moreso the other data involved like the batch details, task details, url details etc. and this was important for the presentation layer.
We knew ahead of time that we had a few key requirements:
- We needed to be able to query only portions of the data since we could potentially have hundreds of thousands of items stored.
- We needed to be able to search screenshots based on url values.
- We needed to be able to sort items in a table based on date created, url, image size and file size.
- We needed to paginate the list.
Here's what the final UI looks like:
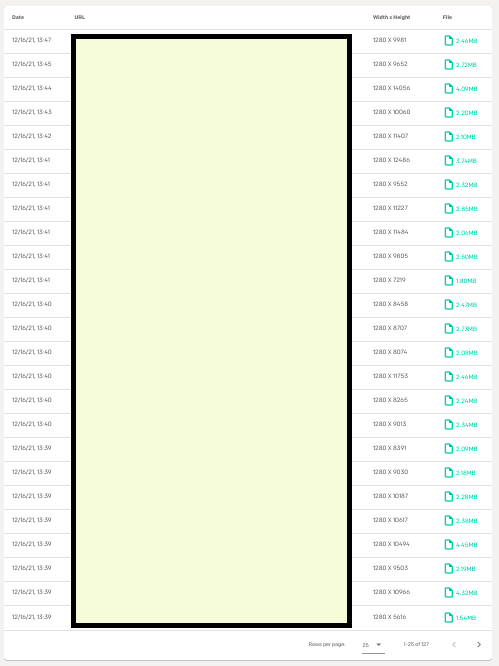
As you can see the table fulfills all of the requirements. It has pagination, you can pick how many items you want to see at a time. Above it there is a search box. Now let's get into the point of this article - things you NEED to know before you decide on using Firestore for your large scale data storage solution:
You are going to need Firestore indexes, a lot of them.
the example above only has 4 fields to sort on, it has a view to show successful screenshots and also a view to show error items. The way you would query that in firestore would be something like this:
// Node.js
const admin = require('firebase-admin')
admin.initializeApp(/* Your credentials */)
const db = admin.firestore()
// The query
await db
.collection('tasks')
// or 'failed' depending on the view
.where('status', '==', 'success')
.limit(25)
.get()
I've skipped the pagination syntax, because it's not really relevant here. This is pretty straight forward right? But if you query this, you'll get items which are sorted on the id of the document, so we need to add:
// The query
await db
.collection('tasks')
// or 'failed' depending on the view
.where('status', '==', 'success')
.orderBy('dateCreated', 'desc')
.limit(25)
.get()
Oops, you'll need an index for that.
So you'll have to go the the dashboard and create a composite index where status=ASCENDING and dateCreated=DESCENDING, but you'll also have to add one for status=ASCENDING and dateCreated=ASCENDING. As a matter of fact you'll have to create such indexes for every combination of your sorting choices and whatever your where clause is (if they aren't on the same field). So the conclusion here is that if you're going to do any sort of complex querying on a large scale Firestore DB, be prepared to create / write and maintain a lot of indexes.
You can also write indexes in a firestore.indexes.json file and deploy them with:
firebase deploy --only firestore:indexes
Firestore indexes are just a small part of the problem
If your data requires any sort of text search, be prepared to pay. Firestore doesn't have text searching fields (as at December 2021), instead they encourage you to install the Algolia extension, where you have to index all your data to make it searchable. This solution costs $$ at large scale, for a feature that probably will only get used a few times if you're an archiving service.
What we did to implement search
We were lucky in the sense that only the URL field needed to be searchable - and because this is an MVP, we opted for the following strategy:
- When storing the url data, we also store an array called
keywords. This contains 'parts' of the url broken up on any characters like.,-,/etc.
Then the search query has to be at least one full part of the url, let's say e.g. the url is: https://example.com/blog/how-to-build-a-rocket, the keywords array would look like:
const keywords = [
'https',
'example',
'com',
'blog',
'how',
'to',
'build',
'a',
'rocket',
]
This is far from ideal, because a user has to know about a keyword before-hand, and this is a show-stopper for us and will likely cause us to migrate part or all of the data to another NoSQL service that allows text search queries. The query for the above would look something like this, everytime someone searches:
await db
.collection('tasks')
// or 'failed' depending on the view
.where('keywords', 'array_contains', userSuppliedKeyword)
.orderBy('dateCreated', 'desc')
.limit(25)
.get()
Aaaand, you need more indexes. Yes, the query above also requires a new index to be built because we're ordering by a different field than what is in the where clause. 😴
The hidden caveats of Firestore
Hidden deep down in the docs under a section called Usage, limits and pricing, there is a heading called Best practices for Cloud Firestore. Here you will find some interesting stuff, like:
Avoid using too many indexes. An excessive number of indexes can increase write latency and increases storage costs for index entries.
But by definition for large scale data - even with just a few simple sorting queries, you're going to create a lot of indexes to access your data.
Avoid writing to a document more than once per second.
Why?
You should not update a single document more than once per second. If you update a document too quickly, then your application will experience contention, including higher latency, timeouts, and other errors.
This could be a showstopper for you, especially if your structure is hierarchical data e.g. a collection within a document of another collection. Because typically this second collection will contain a large amount of items which the containing document requires some metadata about. So each time the subcollection is updated, the parent doc may want to know things like the count or when it was last updated. Fudge!
The one that may bruise your wallet
Here is one that I luckily discovered before our scale went 🚀.
Do not use offsets. Instead, use cursors. Using an offset only avoids returning the skipped documents to your application, but these documents are still retrieved internally. The skipped documents affect the latency of the query, and your application is billed for the read operations required to retrieve them.
Our initial 'pagination' implementation used offset:
// eg
db.collection('tasks').limit(100).offset(100)
The offset would be based on the current page number. You would think that it just skips the first n documents, but it actually counts all the skipped documents to your quota. So let's say e.g. you have 1 million documents. But you're only fetching max 100 at a time when paginating. But if your user skips along, with each 'next page' the reads don't only grow, but they are repeated too. Which blows your quota... Imagine the user getting to page 995 of 1000, where 1000 items are displayed per page. If they click next - they're essentially creating 996,000 reads to your quota (but still only receiving 1000 items). Ouch.
Conclusion
Be safe out there fellow engineers. Set budget alerts and read caveats and limitations FIRST. Study your requirements deeply and assess whether the solution you're looking at is a fit. Then do some more reading. Google your possible problems first e.g. How to sort on multiple fields in 'x technology'.
Hope you enjoyed this one, until next time.